1. 네이버 날씨 웹페이지 가져오기
|
1
2
3
4
5
6
|
|
다음 코드는 네이버 날씨 웹페이지를 가져오는 코드입니다.
pprint는 리스트나 딕셔너리의 데이터가 길경우 보기 좋게 정리해주는 함수입니다.
실행결과 다음과 같은 결과를 얻을 수 있습니다.
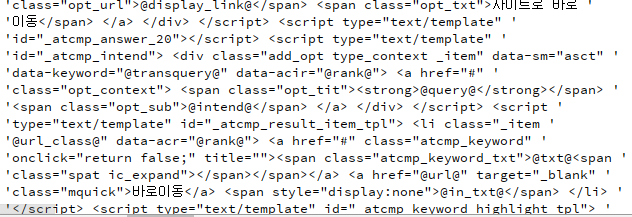
이는 웹페이지의 마우스 오른쪽 클릭 후 페이지 소스보기에 들어가면 볼 수 있는 코드와 동일한 코드입니다. 이를 좀 더 분석하기 쉽도록 파싱작업을 하도록 하겠습니다.
2.파싱작업
|
1
2
3
4
5
6
7
8
9
|
from bs4 import BeautifulSoup as bs
from pprint import pprint
import requests
#pprint(html.text)
pprint(soup)
|
파싱작업 코드를 추가했습니다. 결과는 다음과 같습니다.

해당 웹페이지의 HTML코드가 보기 좋게 정리된것을 볼 수 있습니다.
3. 웹페이지 분석하기
우리는 네이버 날씨 사이트의 미세먼지데이터를 가져오려고 합니다. 데이터를 가져오기 위해서는 해당 데이터가 쓰인 HTML 코드의 태그와 속성을 알아야 합니다. 이는 크롬의 개발자도구를 통해 알 수 있습니다.
개발자도구는 크롬창에서 F12키를 누르면 들어갈 수 있습니다.
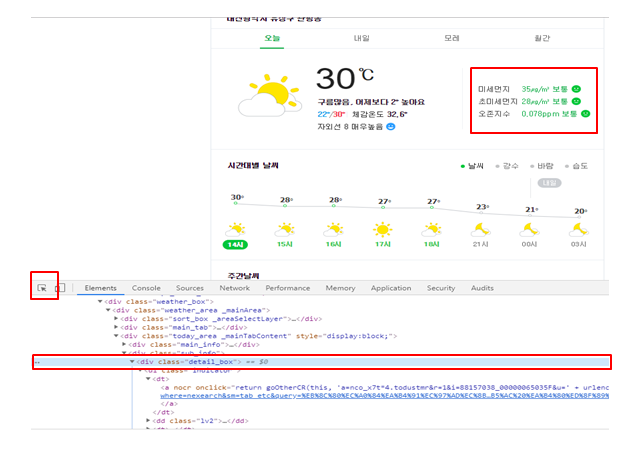
크롬 개발자 모드에서 왼쪽 중단에 있는 Selector를 켜고 원하는 데이터에 마우스를 올려 놓으면 해당 데이터의 태그와 속성을 알아낼 수 있습니다. 이제 알아낸 태그와 속성을 이용하여 필요한 데이터만 추려내는 작업을 하겠습니다.
4. 미세먼지 데이터만 추려내기
|
1
2
3
4
5
6
7
8
9
10
11
12
|
from bs4 import BeautifulSoup as bs
from pprint import pprint # pprint는 리스트나 딕셔너리의 데이터가 길경우 정리해서 보여주는역할
import requests
#pprint(html.text)
#pprint(soup)
pprint(data1)
|
soup.find 메소드를 이용하여 태그가 'div'이고 'class'가'detail_box'인 영역을 추출하였습니다. 결과는 다음과 같습니다.
find메소드는 해당 HTML 문서에 중복된 값이 있는 경우에는 가장 첫 번째 값만 반환합니다.

원하는 영역이 제대로 출력된 것을 확인할 수 있습니다. 이제 해당 영역에서 미세먼지, 초미세먼지, 오존 지수 각각의값을 추출해보도록 하겠습니다.

개발자 도구를 통해 각각의 데이터가 dd태그를 같은 것을 알 수 있었습니다. 다만 'class'는 네이버 자체적으로 미세먼지, 초미세먼지, 오존농도의 값이 달라지면 그 값이 달라지므로 사용할 수 없었습니다. 태그만 사용하여 그 값을 추출해보도록 하겠습니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
from bs4 import BeautifulSoup as bs
from pprint import pprint # pprint는 리스트나 딕셔너리의 데이터가 길경우 정리해서 보여주는역할
import requests
#pprint(html.text)
#pprint(soup)
#pprint(data1)
data2 = data1.findAll('dd')
pprint(data2)
|
findAll메소드를 사용하여 위에서 추출한 영역 중 'dd'태그를 갖는 모든 값을 반환받았습니다. 결과는 다음과 같습니다.

반환된 값이 List로 반된된 것을 확인할 수 있었습니다. 우리가 원하는 것은 미세먼지 데이터이므로 리스트 값만을 취하기 위해 index값을 이용하여 출력해보도록 하겠습니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
from bs4 import BeautifulSoup as bs
from pprint import pprint # pprint는 리스트나 딕셔너리의 데이터가 길경우 정리해서 보여주는역할
import requests
#pprint(html.text)
#pprint(soup)
#pprint(data1)
data2 = data1.findAll('dd')
pprint(data2[0])
|
미세먼지는 리스트의 첫 번째 값이므로 index값으로 0을 넣었습니다. 결과는 다음과 같습니다.

위의 결과를 바탕으로 미세먼지 값이 span 태그를 갖고 class값으로 "num"를 같은 것을 확인하였습니다. 위에서 사용해봤던 find메소드를 이용하여 미세먼지 데이터를 추출해보도록 하겠습니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
from bs4 import BeautifulSoup as bs
from pprint import pprint # pprint는 리스트나 딕셔너리의 데이터가 길경우 정리해서 보여주는역할
import requests
#pprint(html.text)
#pprint(soup)
#pprint(data1)
data2 = data1.findAll('dd')
#pprint(data2[0])
find_dust = data2[0].find('span',{'class':'num'})
print(find_dust)
|
find메소드를 이용하여 값을 출력했습니다. 결과는 다음과 같습니다.

위의 결과는 태그, class 그리고 우리가 원하는 데이터 모두가 출력됩니다. 우리가 원하는 것은 데이터 이므로 데이터만 출력할 수 있도록 .text를 이용하도록 합니다. .text는 태그 내부의 텍스트만 추출할 수 있도록 합니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
from bs4 import BeautifulSoup as bs
from pprint import pprint # pprint는 리스트나 딕셔너리의 데이터가 길경우 정리해서 보여주는역할
import requests
#pprint(html.text)
#pprint(soup)
#pprint(data1)
data2 = data1.findAll('dd')
#pprint(data2[0])
find_dust = data2[0].find('span',{'class':'num'})
print(find_dust.text)
|
.text를 사용하였습니다. 결과는 다음과 같습니다.

이렇게 네이버 날씨 사이트에서 미세먼지 데이터를 추출하는 방법에 대해 알아봤습니다.
python 공부 중에 있습니다. 잘못된 정보가 있으면 댓글에 남겨주시킬 부탁드립니다. 한번 더 배우겠습니다.
감사합니다.
'Language > Python기초' 카테고리의 다른 글
| 2. Anaconda - JupyterNotebook 설치하기 (0) | 2019.07.15 |
|---|---|
| 0. 파이썬 레시피(1) (0) | 2019.07.07 |

